

Improving Vietnamese Fake News Detection based on Contextual Language Model and Handcrafted Features
- University of Information Technology, Ho Chi Minh city, Vietnam Vietnam National University, Ho Chi Minh city, Vietnam
Abstract
Introduction: In recent years, the rise of social networks in Vietnam has resulted in an abundance of information. However, it has also made it easier for people to spread fake news, which has done a great disservice to society. It is therefore crucial to verify the reliability of news. This paper presents a hybrid approach that uses a pretrained language model called vELECTRA along with handcrafted features to identify reliable information on Vietnamese social network sites.
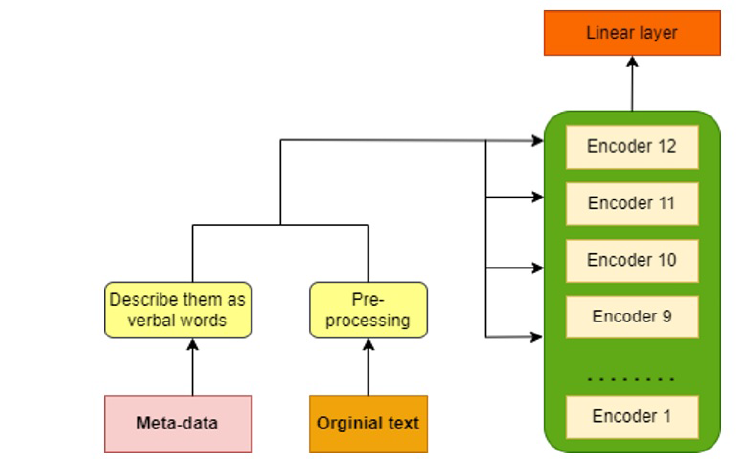
Methods: The present study employed two primary approaches, namely: 1) fine-tuning the model by utilizing solely textual data, and 2) combining additional meta-data with the text to create an input representation for the model.
Results: Our approach performs slightly better than other refined BERT methods and achieves state-of-the-art results on the ReINTEL dataset published by VLSP in 2020. Our method achieved a 0.9575 AUC score, and we used transfer learning and deep learning approaches to detect fake news in the Vietnamese language using meta features.
Conclusion: With regards to the results and analysis, it can be inferred that the number of reactions a post receives, and the timing of the event described in the post are indicative of the news' credibility. Furthermore, it was discovered that BERT can encode numerical values that have been converted into text.