

Feature extraction semilearning and augmented representation for image captioning in crowd scenes
- University of Information Technology, Viet Nam National University Ho Chi Minh City, Viet Nam
Abstract
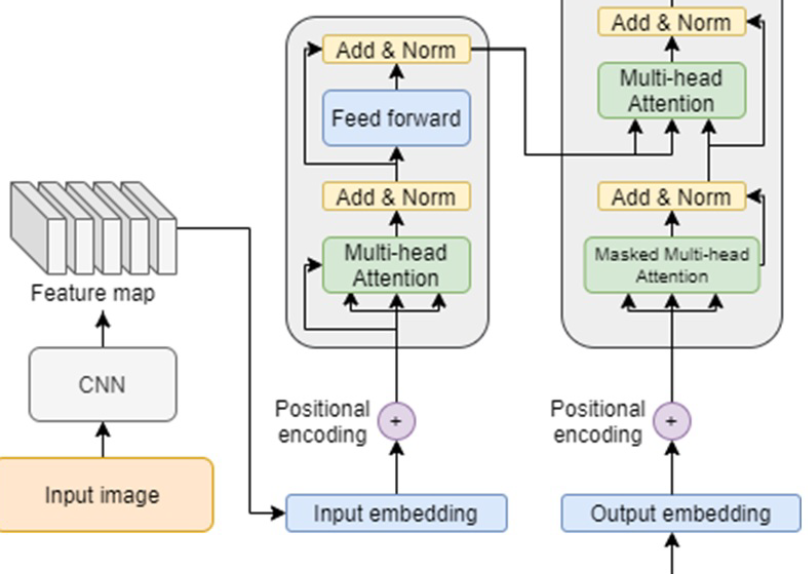
Image captioning has been an interesting task since 2015. The topic lies in the gap between Computer Vision and Natural Language Processing research directions. The problem can be described as follows: Given the input as a three-channel RGB image, a language model is trained to generate the hypothesis caption that describes the images’ contexts. In this study, we focus on solving image captioning in images captured in a crowd scene, which is more complicated and challenging. In general, a semilearning feature extraction mechanism is proposed to obtain more valuable high-level feature maps of images. Moreover, an augmented approach in the Transformer Encoder is explored to enhance the representation ability. The obtained results are promising and outperform those of other state-of-the-art captioning models on the CrowdCaption dataset.